When a feed is included to Friendfeed we can make comments to every post there. Therefore, we can have different threads of comments for the same post, one at the original blog and one at Friendfeed. If we use the FeedAPI module in Drupal we can make something similar as every post in an aggregated feed can become a node (this is the name for unit of content in Drupal) and thus being commented, tagged, rated...
Al this makes fragmented conversations. I read at RWW that some plug ins for Movable Type and Wordpress allow this applications to retrieve the comments that a post originated in one of these platforms has received at Friendfeed and include it in the comments thread. I've been searching but nothing like this seems to be available for Drupal.
Sunday, 7 December 2008
Tuesday, 23 September 2008
Search patterns in a corporate social bookmarking service
This brilliant and useful paper found in Riina's blog explores the search patterns in dogear, a corporate social bookmarking service of a multinational company. This service, only available for company's employees, allows to bookmark internet and intranet links. Another particular feature of this system is the corportate identity of the employees that can not bet hidden by a pseudonym.
The research combines quantitative (log analysis of users actions, followed by cluster analysis of these data) and qualitative (15 interviews to users) methodology in order to explore search patterns within the dogear bookmarking. Three big groups are identificated: Community browsing, Personal search and Explicit search.
 Millen, D., Yang, M., Whittaker, S., Feinberg, J., 2007. Social bookmarking and exploratory search
Millen, D., Yang, M., Whittaker, S., Feinberg, J., 2007. Social bookmarking and exploratory search
URL http://dx.doi.org/10.1007/978-1-84800-031-5\_2
The table (see above) shows the outcomes of the log analysis of users' actions where events represent the action of accessing a particular view (recent posts, another user bookmarks, oneself bookmarks...) and clicks the action of clicking in one result of these views.
Community search is the most common search pattern. Explicit search and personal search (oneself tags) come in second and third place. The more common pattern is to look at the recent post, but other strategies are also used, like looking at what "thought leaders" are bookmarking or what is hot in a particular topic. The interviews have highlighted that this strategies rely on the trust that employees have in the community or in some users. The fact that corporate identity (full name, contact details...) is displayed play an important role here, and also in another search pattern: looking for experts in the company.
Personal search states for users that come back to their own lists of bookmarks and tags. Users that make personal search are frequently those who are active bookmarkers.
While community search is typical of exploratory search (where the goal is not really to retrieve an element but to profile a user, a topic, news...), explicit search is more orientated to retrieve an element. This explains the high percentage of clicks (39%) in these views. Again, the trust in the community play an important role: "...relatively high proportion of clicks... combined with interviews comments suggest that social bookmarking services provide a good way to capture high value pointers to information sources".
The research combines quantitative (log analysis of users actions, followed by cluster analysis of these data) and qualitative (15 interviews to users) methodology in order to explore search patterns within the dogear bookmarking. Three big groups are identificated: Community browsing, Personal search and Explicit search.
 Millen, D., Yang, M., Whittaker, S., Feinberg, J., 2007. Social bookmarking and exploratory search
Millen, D., Yang, M., Whittaker, S., Feinberg, J., 2007. Social bookmarking and exploratory searchURL http://dx.doi.org/10.1007/978-1-84800-031-5\_2
Community search is the most common search pattern. Explicit search and personal search (oneself tags) come in second and third place. The more common pattern is to look at the recent post, but other strategies are also used, like looking at what "thought leaders" are bookmarking or what is hot in a particular topic. The interviews have highlighted that this strategies rely on the trust that employees have in the community or in some users. The fact that corporate identity (full name, contact details...) is displayed play an important role here, and also in another search pattern: looking for experts in the company.
Personal search states for users that come back to their own lists of bookmarks and tags. Users that make personal search are frequently those who are active bookmarkers.
While community search is typical of exploratory search (where the goal is not really to retrieve an element but to profile a user, a topic, news...), explicit search is more orientated to retrieve an element. This explains the high percentage of clicks (39%) in these views. Again, the trust in the community play an important role: "...relatively high proportion of clicks... combined with interviews comments suggest that social bookmarking services provide a good way to capture high value pointers to information sources".
Sunday, 21 September 2008
Networks effects, some links
Dion Hinchliffe made a revision of the topic some time ago and explained that a project that want to exploit their potential need to foster it: "If you have a million people visiting your Web site but you're not leveraging network effects with them (such as by letting them contribute and letting others see and respond to those contributions), then you're probably squandering the greater part of the value of that million person audience."
There is also some links to the theories behind, Meltcalfe, Reed and Bob Briscoe, Andrew Odlyzko, and Benjamin Tilly.

There is also some links to the theories behind, Meltcalfe, Reed and Bob Briscoe, Andrew Odlyzko, and Benjamin Tilly.
Monday, 15 September 2008
Evolution of the percentage of edits made by active users in Wikipedia
Power of the few vs. wisdom of the crowd: Wikipedia and the rise of the bourgeoisie has used a history dump of English Wikipedia (58 millions of editions, 4,7 millions of pages). To process this data the have used a powerful environment based in Hadoop. The have calculated the number of edits made and the changes in content between edits (counting words, not lines). Users has also been classified by number of edits, and the editions have been grouped by types of users (from very active to sporadic).
Comparing Wikipedia coverage by domain areas
An Analysis of Topical Coverage of Wikipedia uses a random sample of 3000 articles. These articles have been classified by subjects. The extend of each article has been measured by the size of HTML page in kilobytes. The number of edits for every page has also been recorded.
Measuring Wikipedia
Measuring Wikipedia has used dumps of German, Japanese, Danish and Croatian Wikipedias. While German and Japanese are large-size wikipedias (second and third), the other two are example of middle-size and small size. These date has allowed to study the growth of wikipedia (database size, number of words, internal links, users and active users...), the proportion between articles and related talk pages, articles size distribution, proportion between articles and authors, articles and edits...
Web based bibliographic annotations specifical patterns
Tagging tagging. Analysing user keywords in scientific bibliogra-phy management systems use a dump containing all post uploaded to Connotea (resource name, URL, tags). This dump has been retrieved using the open API of this application to explore tagging patterns.
Data processing:
A team of researchers has examined these data and has made some suggestions for linguistic and functional categories of tags. These suggestions were discussed in a workshop and integrated in a preliminary category model. In a second phase, this category model has been verified.
Data processing:
A team of researchers has examined these data and has made some suggestions for linguistic and functional categories of tags. These suggestions were discussed in a workshop and integrated in a preliminary category model. In a second phase, this category model has been verified.
Tuesday, 22 July 2008
Metaphors of learning
Oldaily points to an article where different metaphors of learning are classified. Before reading the article (Learning and organizations: towards cross-metaphor conversations) we can have a look at the post linked by Oldaily. Good for a slide to start discussion in a workshop.
Information overload cost money
On the one hand, social media is a filter of information, that's what we say and theorize. On the other, it brings a flood of new sources to check. Even more, in a read/write web, users are not only checking new information, they are also classifying, commenting or creating new content. That's makes a lot of time. I don't think it's based on any reliable data but I love the picture below.
Another post from the same blog discuss the outcomes of a research stating that Web 1.0 information oveload causes in the US 650 billions in wasted productivity. "The findings reveal that a typical information worker checks his or her email more than 50 times per day, uses IM 77 times, and visits 40+ web sites. These numbers were calculated by tracking software installed on the machines of the 40,000 people taking part in the study."
Strategies to manage this are a recurrent subject in blogs I read but we can not find more than make your own recipe of concentration, routine and filters.

Another post from the same blog discuss the outcomes of a research stating that Web 1.0 information oveload causes in the US 650 billions in wasted productivity. "The findings reveal that a typical information worker checks his or her email more than 50 times per day, uses IM 77 times, and visits 40+ web sites. These numbers were calculated by tracking software installed on the machines of the 40,000 people taking part in the study."
Strategies to manage this are a recurrent subject in blogs I read but we can not find more than make your own recipe of concentration, routine and filters.
Wednesday, 9 July 2008
A quick link to last edu buzz
on edupunk - D'Arcy Norman dot net
It’s a movement away from what has become of the mainstream edtech community - a collection of commercial products produced by large companies. Edupunk is the opposite of that. It’s DIY. It’s hardcore. It’s not monetized. It’s not trademarked. It’s not press-released. It’s not on an upgrade cycle. It’s not enterprise. It’s not shrinkwrapped.
Internat, las aulas y los jóvenes
Comentario de Julen en un post sobre innovación y ciberespacio
Es una realidad que los jóvenes se socializan en buena parte a través de aprendizajes informales que suceden fuera de las aulas y que en buena parte ahora también están basados en el uso de las tecnologías. Estos usos les sirven para generar sus propios espacios de intimidad al margen de los adultos en una extraña mezcla de exhibicionismo y privacidad.
Wednesday, 2 July 2008
Nature network
I still don't know if the idea of science 2.0 is inside or outside of my research focus. Anyway, there is something moving on. I just found a network related to Nature where one of the more active groups is named "Scientific researchers and Web 2.0: Social not working".
If a domain-specific portal can be an information hub for academics, there must be some links between this and science 2.0.
An article from the Guardian on the site
If a domain-specific portal can be an information hub for academics, there must be some links between this and science 2.0.
An article from the Guardian on the site
Wednesday, 25 June 2008
Is Google making us stupids?
Nicholas Carr usa este provocativo título para hacer una reflexión sobre la pérdida del hábito de concentración en la lectura y los posibles efectos en nuestra forma de pensar. También hace un paralelismo entre el Taylorismo industrial y el "taylorismo" mental que supone la forma en que Google sistematiza nuestra búsqueda de conocimiento "Ambiguity is not an opening but a bug to be fixed"
Un resumen del debate que se ha formado alrededor
Un resumen del debate que se ha formado alrededor
Friday, 20 June 2008
Plone como plataforma de colaboración
Post sobre las posibilidades de crear un entorno de colaboración con Plone (en 2005)
How Plone Can Become Kick-Ass Community Collaboration Software
How Plone Can Become Kick-Ass Community Collaboration Software
Tuesday, 17 June 2008
Redes sociales: saturación o expansión
Este post cita dos fuentes que ofrecen una de cal y otra de arena para las redes sociales. Por un lado tenemos otro post que explica que los resultados de Myspace y Facebook en ComScore se están estancando.
Por otra parte tenemos otro estudio que dice que la penetración de la redes en nuestra sociedad es creciente y que se está ganando un sitio al lado de la prensa
"concludes that what was once only a niche activity is now a growing trend that has more people joining every day. According to the report, one out of every four people visit social networking sites, and half of those that do, do so on a daily basis. The trend is so prevalent, says Lynn Franco, Director of The Conference Board Consumer Research Center, that it's going to extend beyond just personal use. "The next growth wave will be expanding and incorporating these networks into our business lives," she claims."
Periodismo ciudadano y situaciones de emergencia
Este post relata como la Cruz Roja ha usado herramientas como wordpress, Flickr, YouTube o Twitter para crear canales de comunicación en situaciones de emergencia (inundaciones y tornados). En definitiva, una sala de prensa online con contribuciones de los usuarios.
Wednesday, 4 June 2008
Análisis de redes sociales
La llegada de Internet y la consecuente huella digital que todos dejamos en nuestro uso diario han transformado esta técnica de análisis. En los inicios de este tipo de investigación el mayor problema era la captación de datos; actualmente el problema se sitúa en su procesamiento.
Este artículo repasa la evolución de las técnicas de análisis y los elementos fundamentales de estas estructuras: relaciones, posición, motivos, configuración.
En este enlace hay además un resumen de una exposición del autor sobre herramientas disponibles para el análisis
Este artículo repasa la evolución de las técnicas de análisis y los elementos fundamentales de estas estructuras: relaciones, posición, motivos, configuración.
En este enlace hay además un resumen de una exposición del autor sobre herramientas disponibles para el análisis
Saturday, 31 May 2008
E-konsulta, servicio de soporte a las TICs en las Pymes
Friday, 30 May 2008
Monday, 12 May 2008
Power Law of contribution (2)
Hace algunos meses recogía unos enlaces sobre la distribución de las contribuciones entre los usuarios de un sitio social. Otro de los miembros del grupo de Erik Duval ha presentado un paper con un estudio cuantitativo que viene a confirmar lo que se manejaba ya como un principio admitido en la práctica: un porcentaje muy escaso de los usuarios es responsable de la gran mayoría de los contenidos en sitios como Wikipedia o Youtube.
 No hay sorpresas, se confirma lo que para muchos era una verdad indiscutible; de hecho, aunque el artículo dice que es la primera vez que se demuestra, The Guardian publicó hace ya tiempo los resultados de un estudio similar. Sin embargo, como siempre, no todo es tan sencillo. Aunque solo me lo he mirado un poco, algunas de las conclusiones llaman la atención:
No hay sorpresas, se confirma lo que para muchos era una verdad indiscutible; de hecho, aunque el artículo dice que es la primera vez que se demuestra, The Guardian publicó hace ya tiempo los resultados de un estudio similar. Sin embargo, como siempre, no todo es tan sencillo. Aunque solo me lo he mirado un poco, algunas de las conclusiones llaman la atención:
 No hay sorpresas, se confirma lo que para muchos era una verdad indiscutible; de hecho, aunque el artículo dice que es la primera vez que se demuestra, The Guardian publicó hace ya tiempo los resultados de un estudio similar. Sin embargo, como siempre, no todo es tan sencillo. Aunque solo me lo he mirado un poco, algunas de las conclusiones llaman la atención:
No hay sorpresas, se confirma lo que para muchos era una verdad indiscutible; de hecho, aunque el artículo dice que es la primera vez que se demuestra, The Guardian publicó hace ya tiempo los resultados de un estudio similar. Sin embargo, como siempre, no todo es tan sencillo. Aunque solo me lo he mirado un poco, algunas de las conclusiones llaman la atención:- No existen diferencias importantes en la distribución de las contribuciones entre contenidos que demanda poco o mucho esfuerzo (un enlace o crear un vídeo)
- A pesar de que Pareto se puede aplicar, hay que seguir midiendo para evitar sorpresas
Saturday, 10 May 2008
Analysis of the supporting websites for the use of instructional games in K-12 settings
This paper identifies resources to be included in a website designed to facilitate the integration of instructional games in K-12 settings. Guidelines and supporting components are based on a survey of K-12 educators who are integrating games, an analysis of existing instructional game websites, and summaries of literature on the use of educational software in K-12 settings and teacher technology training. The results indicate that educators face three main challenges when integrating games, including: (1) curriculum integration, (2) technical and logistical requirements, and (3) teacher training. To overcome these challenges, K-12 educators should be provided with: (1) curriculum resources, (2) game technical information and support, and (3) communication tools. Websites designed to facilitate the use of instructional games should be designed with appropriate structures (ie, grid, web, hierarchy) to optimise organisation and simplicity. In addition, the websites should include teacher training that (1) apply a teacher training model, (2) address National Educational Technology Standards, (3) present contents in small doses, (4) make training and information as accessible as possible, and (5) model and mentor the use of instructional games.
Friday, 2 May 2008
Reflexión sobre ponderación y calidad de los contenidos en Digg
Este post se hace eco de otro que cuestiona la ponderación positiva de algunos contenidos susceptibles a atraer a nuevos usuarios frente a otros contenidos sobre tecnología más afines a los usuarios que llevan más tiempo usando la herramienta. De acuerdo a sus argumentos, la calidad de los contenidos está saliendo perjudicada.
Clasifico esta entrada con la etiqueta recommenders, aunque no tengo claro si puede clasificar Digg como un "recommender system" semejante a MyStrands o Pandora.
Clasifico esta entrada con la etiqueta recommenders, aunque no tengo claro si puede clasificar Digg como un "recommender system" semejante a MyStrands o Pandora.
Informe del JISC sobre los "beneficios tangibles" del e-learning
Informe manejable (aprox 40 pag.) que puede ayudarme a definir el espectro de las prácticas del e-learning.
Outputs from the project include a JISC Briefing Paper3, a 41-page publication and the full set of 37 detailed case studies available online. Case studies can be accessed by institution, by section and by theme, with links also mapping them to Higher Education Academy subject centres and to JISC e-Learning activity areas.
Internet cumple 15 años
Unas líneas para tomar nota de una cuestión anecdótica pero al mismo tiempo importante. Este artículo de ABC (periódico australiano) recoge las declaraciones de Tim Berners-Lee en los actos del conmemoración de la liberación del código de la WWW. Al contrario que Gopher, AOL, o Compuserve que no hicieron lo mismo, algunos de los investigadores de CERN, centro europeo para la energía atómica que se encuentra entre Francia y Suiza, convencieron a sus jefes de que poner a disposición de todo el mundo este código iba a permitir una difusión mucho mayor. Naturalmente, este fue solo un pasito entre los avances de otras muchas organizaciones. En este artículo hay más información sobre el papel desempeñado por el CERN en el desarrollo de las tecnologías que sustentan Internet.
Wednesday, 5 March 2008
Collective intelligence: una tendencia emergente a 4 años, en Horizon report 2008
El informe señala este concepto como una tendencia que alcanzaría su grado de madurez en 4 o 5 años. Se distingue entre un modelo explícito (como la Wikipedia) y otro implícito, en la onda del filtrado colaborativo. Se citan experiencias en astronomía donde la colaboración de los usuarios ha permitido nuevos descubrimientos. Se citan referencias.
http://www.nmc.org/pdf/2008-Horizon-Report.pdf
http://www.nmc.org/pdf/2008-Horizon-Report.pdf
Monday, 25 February 2008
Connective and collective intelligence
Downes recoge en dos post seguidos (primero, segundo) una distinción de Siemens entre estos dos conceptos que expone las siguientes definiciones:
Collective intelligence: "is a form of intelligence that emerges from the collaboration and competition of many individuals". According to this definition, intelligence is not a product such as information or knowledge, but rather a capacity to come function together to achieve a particular task or intention.
I don't have concerns with the process of collective intelligence as presented here, but I am concerned with the identity-less product which is the consummation of individual work and what is often presented as the work of the collective.
Connective intelligence: individual creation of information, ideas, and concepts which are then shared with others, connected, and re-created and extended based on the interaction.
Simply, collective means blending together. Connective means connecting while retaining the original (though others may build on it in their own spaces).
Si lo entiendo bien, estos dos conceptos distinguen entre la disponibilidad/capacidad de obtener información y conocimiento de nuestra interacción en redes anónimas (en el sentido de que confiamos en una tendencia del conjunto del usuario, no en personas concretas a quién reconocemos su criterio) y nuestras redes más personales. En estas redes cercanas, nuestra identidad no se difumina; en la nube de tags de del.icio.us síThursday, 31 January 2008
¿Tipos o grados de contenido generado por el usuario?
Hace unas semanas tuve un cruce entre dos post. Julen aludía a un artículo del País donde se constataba el escaso porcentaje de los usuarios de páginas Web 2.0 que realmente contribuyen. Es una idea parecida a la ley del 1% de Arthur. Julen constataba como en un espacio de participación masivo, como es Internet, un porcentaje ridículo puede llegar a ser suficiente.
Por otra parte, Riina Vuorikari enlazaba este gráfico de Ross Mayfield.
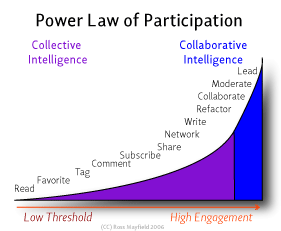
Las distintas formas de contribución de un usuario forman una curva ascendente que significan que están más implicado. En el update del post hay algunos datos y enlaces más sobre esta idea, aunque nada parecido a un paper. Desde el punto de vista individual, no tiene mucho sentido. Cada usuario estará guiado por sus necesidades y participará de acuerdo a ellas, de modo que los itinerarios de implicación pueden ser muy diversos, pero desde el punto de vista del conjunto de los usuarios de un sitio, es una pregunta que nos podemos plantear: ¿contribuye la frecuencia de contribuciones de menor grado a aumentar la frecuencia de las contribuciones de mayor grado?
Por otra parte, Riina Vuorikari enlazaba este gráfico de Ross Mayfield.
Las distintas formas de contribución de un usuario forman una curva ascendente que significan que están más implicado. En el update del post hay algunos datos y enlaces más sobre esta idea, aunque nada parecido a un paper. Desde el punto de vista individual, no tiene mucho sentido. Cada usuario estará guiado por sus necesidades y participará de acuerdo a ellas, de modo que los itinerarios de implicación pueden ser muy diversos, pero desde el punto de vista del conjunto de los usuarios de un sitio, es una pregunta que nos podemos plantear: ¿contribuye la frecuencia de contribuciones de menor grado a aumentar la frecuencia de las contribuciones de mayor grado?
Tuesday, 8 January 2008
Beyond OER
John Seely Brown was at the UOC and Ismael Peña give us a good and concise report of his speaking. The subject was OER and the speaker comes with the question on how to go further in openness for learning after the free provision of materials. And says:
Understanding is socially constructed.
This is not new from the pedagogic perspective, but it is interesting to think that it's not enough to give free materials, there is a lot to do in the field of open discussion, social information retrieval... Well, I'm not catching all the interesting clues of this idea, this is just a quick post to remember to read it again, and to go further with three other links at the bottom of the post.
Understanding is socially constructed.
This is not new from the pedagogic perspective, but it is interesting to think that it's not enough to give free materials, there is a lot to do in the field of open discussion, social information retrieval... Well, I'm not catching all the interesting clues of this idea, this is just a quick post to remember to read it again, and to go further with three other links at the bottom of the post.
A definition of social information retrieval?
It's pretty evident that information retrieval in the web rely, among other things, in mechanism based in a bottom-top logic. Pagerank harness individual decisions to give relevant results in the queries, and this has a social and "democratic" logic and, up to now, it's the best way to retrieve information from the never-ending WWW.
We can think of this outside the bounds of the Internet. We do search for information in brick and mortar life looking at what other people do or tell us they do (word of mouth). We can do a lot of this in the Internet, a perfect place to nose around, and even better since we have applications like del.icio.us or myspace that invite to do social navigation. Furthermore, other applications have mechanism to retrieve our opinions (digg, or any other place where we are asked to rate) o simply do the job for us, as Amazon or Pandora collaboratively filtering.
Retrieving (selected) information is very related to what a users want to do in a thematic portal, so, as this is the context of my phD, I bookmarked on the spot the SIRTEL07 workshop when I first saw it. Despite the interest of the papers I found there, no one of them gave me a clear definition. So I googled around and got this:
The paper in interesting but still is too much centered on searchers and not on social navigation and all the other stuff I mentioned before. Eventually I found better, but still in press: a book on social information retrieval that is considering it very widely, from algorithms to social bookmaking and even design.
We can think of this outside the bounds of the Internet. We do search for information in brick and mortar life looking at what other people do or tell us they do (word of mouth). We can do a lot of this in the Internet, a perfect place to nose around, and even better since we have applications like del.icio.us or myspace that invite to do social navigation. Furthermore, other applications have mechanism to retrieve our opinions (digg, or any other place where we are asked to rate) o simply do the job for us, as Amazon or Pandora collaboratively filtering.
Retrieving (selected) information is very related to what a users want to do in a thematic portal, so, as this is the context of my phD, I bookmarked on the spot the SIRTEL07 workshop when I first saw it. Despite the interest of the papers I found there, no one of them gave me a clear definition. So I googled around and got this:
Social information retrieval systems are distinguished from other types of ir (Information retrieval) systems by the incorporation of information about social networks and relationships into the information retrieval process.
The paper in interesting but still is too much centered on searchers and not on social navigation and all the other stuff I mentioned before. Eventually I found better, but still in press: a book on social information retrieval that is considering it very widely, from algorithms to social bookmaking and even design.
Thursday, 3 January 2008
I want my data back
Downes tell us about a guy who has been fired from Facebook: "I am working with a company to move my social graph to other places and that isn't allowable under Facebook's terms of service." Maybe what this guy was doing was forbidden, but what Facebook did, deleting his account, is also forbidden. Anyway, nor Google neither anyone in the web 2.0 arena allow you to make a back up of your data, even if Open Social business model, data can go beyond the bounds of the silo where the user out them.
Interesting link about open networks http://www.dataportability.org/
Interesting link about open networks http://www.dataportability.org/
Wednesday, 2 January 2008
A matter of collaboration
Can we really speak of a collective intelligence merging from the action of scattered users? Can we speak about a will of collaboration or, maybe, it's just that particular and collective interests are matching together? Do we contribute because social tools are useful for us, because we love the idea of open content or because we are trying to achieve a digital reputation? To which extent one or the other motivations are working?
I hear quite often that users begin to use social software because of a personal interest, like the advantage of ubiquity when bookmarking at del.icio.us, and the sum of all these interest is what make new value for the community. Right, but these instrumental goals come together with other social goals, because users are aware that there are not taking notes in their personal notebook and also aware that one tag or another can make more people find these personal bookmarks.
So instrumental and social goals meet together when a user is deciding whether to collaborate and make open its content, links... or keep it in his own folders. Peter Kollock Social dilemmas, anatomy of cooperation is maybe a good perspective to study what's happening between the individual and the collective, even more when we see that this author has also edited a book where the nature of virtual communities is also explored: Communities in cyberspace
And on top of this we have the digital divide matter: a few days ago, danah boyd talked about a first PEW report about adults footprints. Digital footprints is more about privacy than contributing and adding value, but the idea is that adults are very likely to leave information about themselves but they are saying just the opposite, specially to their children. A few days later another report is commented in the same blog. This one is about young people, "teens are much more protective of the content they post online than adults are".
I hear quite often that users begin to use social software because of a personal interest, like the advantage of ubiquity when bookmarking at del.icio.us, and the sum of all these interest is what make new value for the community. Right, but these instrumental goals come together with other social goals, because users are aware that there are not taking notes in their personal notebook and also aware that one tag or another can make more people find these personal bookmarks.
So instrumental and social goals meet together when a user is deciding whether to collaborate and make open its content, links... or keep it in his own folders. Peter Kollock Social dilemmas, anatomy of cooperation is maybe a good perspective to study what's happening between the individual and the collective, even more when we see that this author has also edited a book where the nature of virtual communities is also explored: Communities in cyberspace
And on top of this we have the digital divide matter: a few days ago, danah boyd talked about a first PEW report about adults footprints. Digital footprints is more about privacy than contributing and adding value, but the idea is that adults are very likely to leave information about themselves but they are saying just the opposite, specially to their children. A few days later another report is commented in the same blog. This one is about young people, "teens are much more protective of the content they post online than adults are".
Tuesday, 1 January 2008
Personal mediated communication and the concept of community
(pre- reading notes) This chapter explores the relationship between the mediated communication and the creation and evolution of communities. After making a revision of the definitions of community that can be relevant, the chapter explores "examines mediated communications, especially the Internet and mobile phone technology, and their potential impact on social relationships within communities"
This link was found in an open Syllabus of a course og H. Reinghold.
This link was found in an open Syllabus of a course og H. Reinghold.
Subscribe to:
Posts (Atom)
